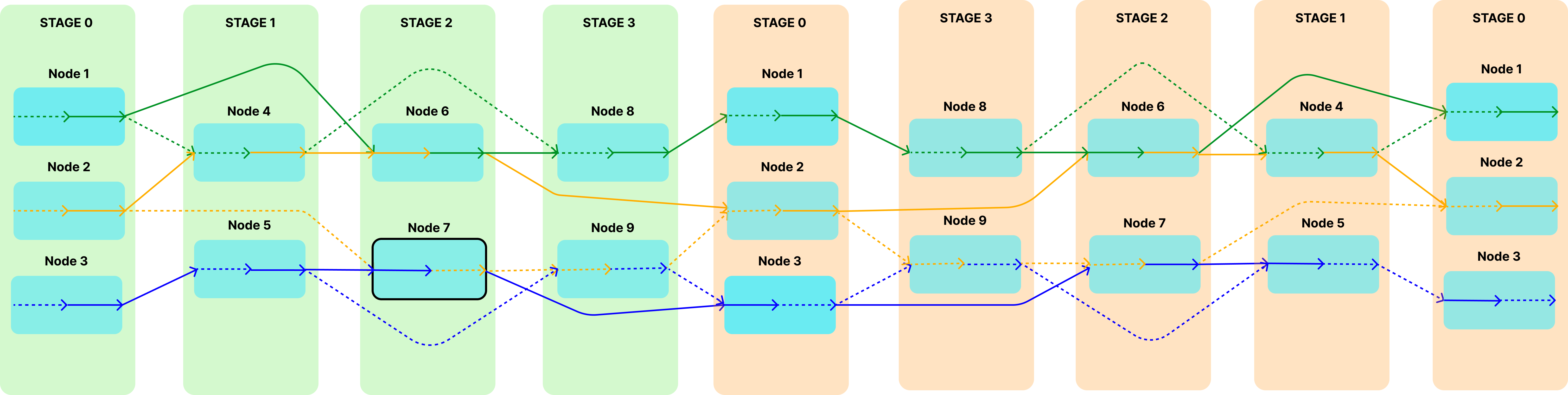
Heterogeneity aware pipeline-parallel technique that trains a fraction of the model per microbatch. Such training provides significant training time speed up and produces models robust to layer omission during inference.